三范式定义
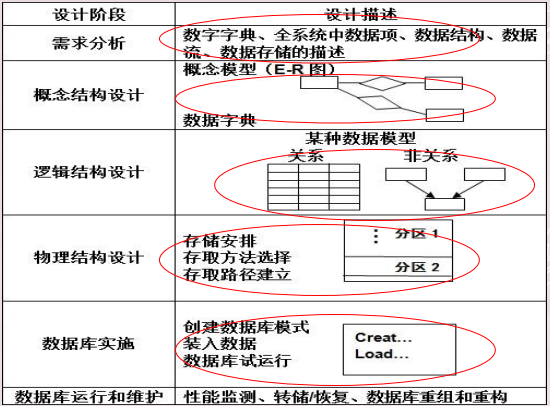
数据库设计步骤
(一个好的工具,可以帮助我们更好的学习知识)。
存储引擎
MySQL中的数据用各种不同的技术存储在文件(或者内存)中。这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。
MySQL中MyISAM与InnoDB的区别,面试题:至少五点
- InnoDB支持事务,MyISAM不支持事务。
- InnoDB支持行级锁,MyISAM支持表级锁。
- InnoDB支持MVCC, MyISAM不支持。
- InnoDB支持外键,MyISAM不支持。
- InnoDB不支持全文索引,MyISAM支持。
数据库ACID+事务+隔离级别
(1)原子性:事务中的操作是一个不可分割的整体单元,要么全部都做,要么全部不做。
(2)一致性:事务执行前后数据库都必须处于一致性状态。
(3)隔离性:通常来说,一个事物所做的修改在最终提交之前对其余事务是不可见的。这里就涉及到事务的隔离级别的问题了。
(4)持久性:一旦事务提交完成,修改就是永久的,即使服务器宕机也不会影响到。
事务
我们可以通过设置 AUTOCOMMIT 变量来启动或则禁用自动提交模式。 设置1表示启用AUTOCOMMIT,0表示禁用AUTOCOMMIT。
MySQL中默认的是采取自动提交模式(AutoCommit),
- 只要不是显示的开启一个事务,每个查询操作都被当做一个事务执行提交的操作。
- 显示的开启一个事务开启,当用户执行commit命令时当前事务提交。从用户执行start transaction命令到用户执行commit命令之间的一系列操作为一个完整的事务周期。若不执行commit命令,系统则默认事务回滚。
事务并发带来的数据问题
- 脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
- 不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
- 幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
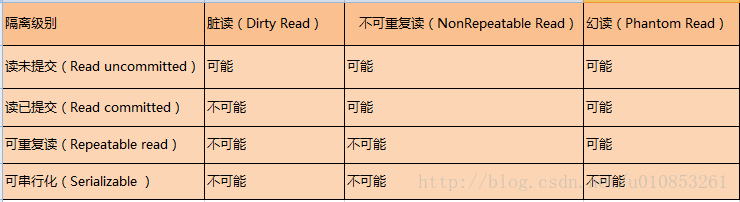
隔离级别
隔离级别(isolation level),是指事务与事务之间的隔离程度。
Read Uncommitted(未提交读):在该隔离级别,所有事务都可以看到其他未提交事务的执行结果。读取未提交的数据,也被称之为脏读(Dirty Read)。该级别用的很少。
Read Committed(提交读):一个事务只能看见已经提交事务所做的改变。这种隔离级别也支持不可重复读(Nonrepeatable Read),同一事务的其他实例在该实例处理其间可能会有新的commit,所以同一select查询可能返回不同结果。
Repeatable Read(可重复读)MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。导致另一个棘手的问题:幻读 (Phantom Read)。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC)机制解决了该问题。
Serializable(可串行化)这是最高的隔离级别,它强制事务都是串行执行的,使之不可能相互冲突,从而解决幻读问题。换言之,它是在每个读的数据行上加上共享锁。在这个级别,可能导致大量的超时现象和锁竞争。
MySQL索引
在mysql中索引是在存储引擎层实现的,不同的存储引擎索引的实现方式不同。
常用的有两类BTree和哈希索引Hash、全文索引、空间数据索引RTree
Btree索引:支持全值索引、匹配最左前缀(搜索时注意条件的顺序,否则不适用索引)、匹配列前缀、精确匹配列等。
哈希索引:只有精确匹配所有列的查询才有效。只要Memory支持哈希索引(非唯一哈希索引,相同的索引会以链表的形式存储在索引中)
空间数据索引(R-Tree):无需前缀查询,从所有维度查询数据。
全文检索: 查找文本中的关键词,类似于搜索引擎做的事情。
日志
- 系统故障时,建议首先查看错误日志,以帮助用户迅速定位故障原因。
- 记录数据的变更、数据的备份、数据的复制等操作时,打开二进制日志。默认不记录此日志,建议通过--log-bin 选项将此日志打开。
- 如果希望记录数据库发生的任何操作,包括 SELECT,则需要用--log 将查询日志打开, 此日志默认关闭,一般情况下建议不要打开此日志,以免影响系统整体性能。
- 查看系统的性能问题, 希望找到有性能问题的SQL语 句,需要 用 --log-slow-queries 打开慢查询日志。对于大量的慢查询日志,建议使用 mysqldumpslow 工具 来进行汇总查看。
视图
视图最简单的实现方法是把select语句的结果存放到临时表中,
- 视图是一个虚表,建立在存在的表数据基础上。
- 在提升性能能力不强,更大的作用是专注于逻辑。
- 在一定情况下不能采用更好的查询优化查询性能。
存储过程
存储过程类似于代码中的函数,只能处理特定的任务。
存储过程的优点:
- 能够将代码封装起来,保存在数据库中,编程语言可以进行调用。
- 存储过程是一个预编译的代码块,已经完成了解析、预处理、查询优化过程可以直接执行。
- 一个存储过程替代大量T_SQL语句 ,可以降低网络通信量,提高通信速率。
存储过程的缺点:
- 每个数据库的存储过程语法几乎都不一样,十分难以维护(不通用)。
- 业务逻辑放在数据库上,难以迭代。
参考博客